


Google Analytics regex (i.e. regular expressions) is an under-appreciated skill set. But if you want to filter or target beyond the basics, a good grip on regex will give you Analytics superpowers.
Regular expressions are used beyond analytics and marketing, but for the purpose of this article, we’ll cover the tactical Google Analytics stuff that delivers deeper insights, data organization, and advanced targeting. Then we'll look at search engine marketing use cases.
Get brand new analytics strategies straight to your inbox every week. 23,739 people already are!
Google Analytics RegEx: What is It?
Regular expressions are special text strings for describing search patterns.
Huh?
In relation to analytics, regular expressions help you find, define, and extract stuff. Even more specifically, with Google Analytics, they can help you create more flexible definitions for things like view filters, goals, segments, audiences, content groups, and channel groupings.
Basically, they are predefined characters or a series of characters that broadly or narrowly matches and selects patterns in your digital analytics data. They’re a general tool that can be used in many ways (tons of programming languages and tools allow regex). But in Analytics, we’re going to mainly use them to match patterns in data.
It’s not just useful in Analytics, of course. Especially, if you’re a Google Tag Manager user or if you’re running complicated targeting on your A/B tests, you’ll be using a lot of regex. As Chris Mercer, founder of MeasurementMarketing.io, says:
“We use regex on a daily basis. It helps us clearly define everything from funnel steps in a Google Analytics goal, to a specific triggers in Google Tag Manager.”
However, if you’d like to do a deep dive and really learn regular expressions, here are a few resources (not necessary for basic stuff in Google Analytics, and probably for someone of more technical prowess):
- Regular Expressions: The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
You can also learn interactively through something like RegexOne or RegexR, both of which are cool. But let’s move past that and walk through the most commonly used Google Analytics regex characters, so you can start putting this to use.
Google Analytics RegEx Cheat Sheet
Look at the following Google Analytics regex characters as a sort of cheat sheet -- you probably won’t use them right away, but briefly going over what you’re capable of with regex will allow you to search for the answer when it’s necessary.
For a brief summary, I haven’t found anything more condensed and to the point than this guide:

However, you can see that, with that alone as a reference, it’s a bit vague and ambiguous. So let’s walk through the most commonly used Google Analytics regex while showing corresponding use cases.
Pipe (|)
When you want to say “OR” you should use a pipe (|). As in “This | That” which would mean “This OR That”.
If you’re an avid user of Google Analytics segments, you’re already used to using OR logical operators.
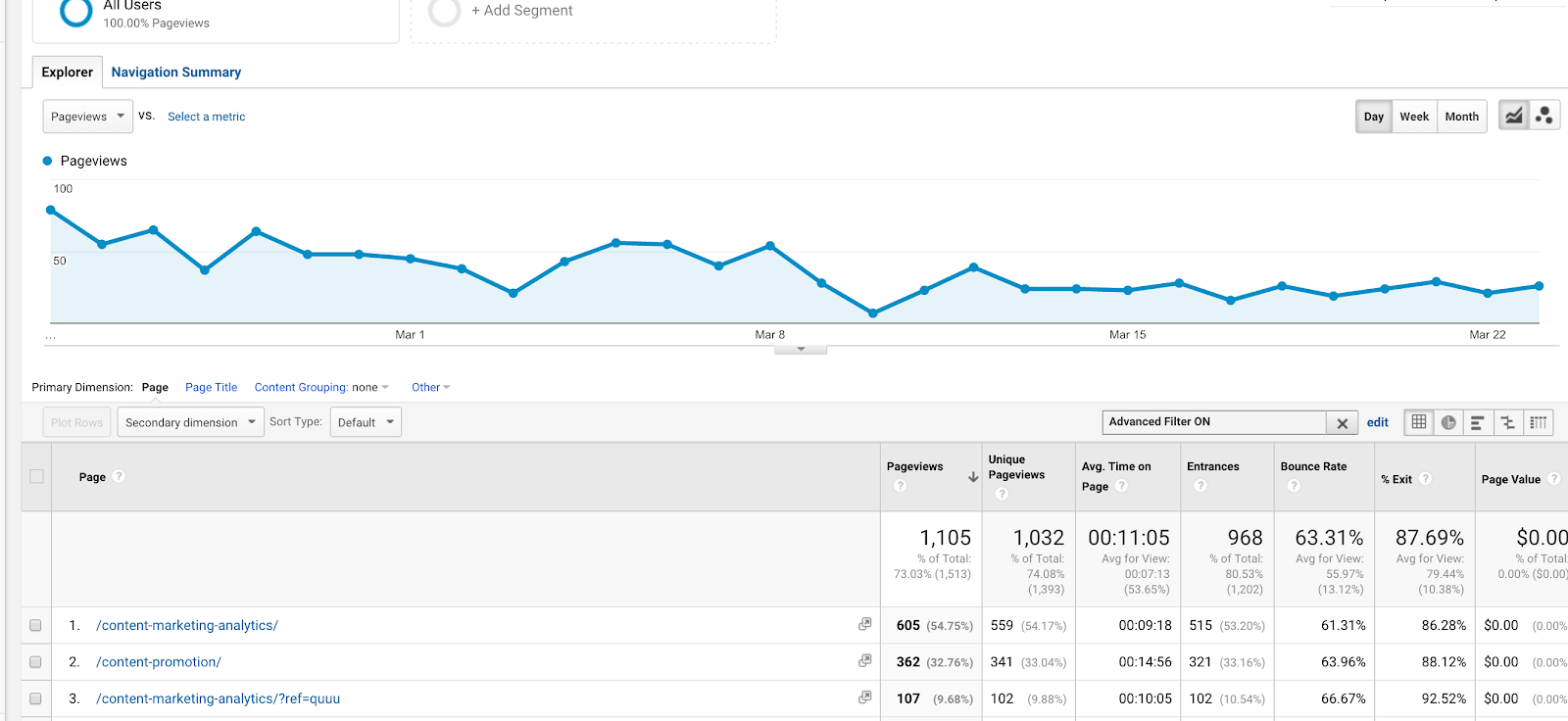
This is one of the simpler and more common regular expressions used in Google Analytics. It has many applications, though one of the most utilized might be when setting up goals. If you have two thank you pages with distinct URLs (/thank-you/ and /subscription-confirmed/), but you’d like to track both of them as a goal completion, you can use this regular expression.
You can also use it in filters. Say you wanted to view a behavior report on two articles (on Content Marketing Lessons and Content Analytics), with the URLs /content-marketing-analytics/ and /content-marketing-lessons/. You could write, as a filter, “content-marketing-analytics|content-marketing-lessons” and get only those articles.
Backslash (\)
The backslash (\) is another straight forward and commonly used regular expression in Google Analytics. It means “consider the next character plain text, and not regex.”
In other words, there are many regular expressions that appear in plain text, such as the dot, question mark, and others, that we need to clarify whether they’re to be read as regular expressions or plain text.
A common query string online is used when someone searches for something on your site. For example, when I search for “small dog toys” on petsmart.com, this is the query string that comes up:
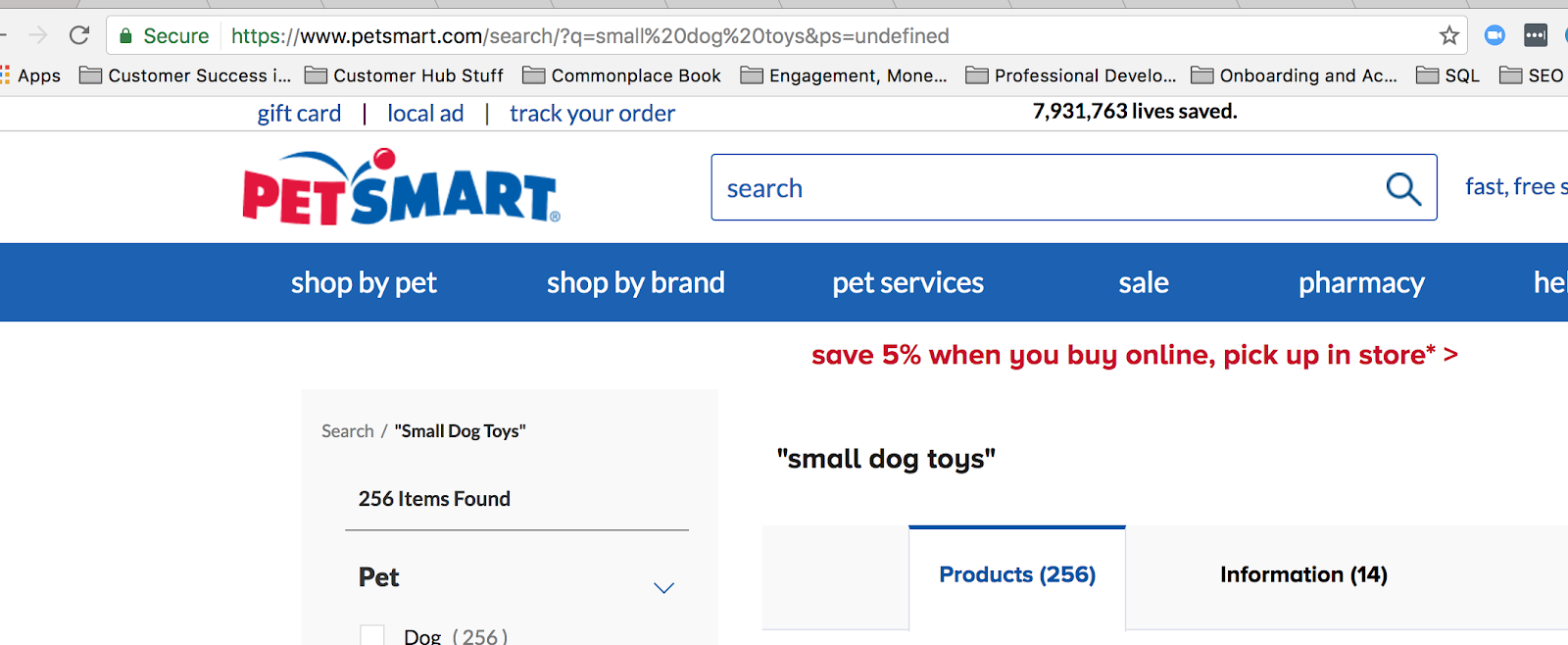
The question mark here signifies that an on-site search has taken place, but the question mark is also a commonly used regular expression in Google Analytics. Therefore, we have to clarify when using a backslash, that in this case, the question mark should be read as plain text.
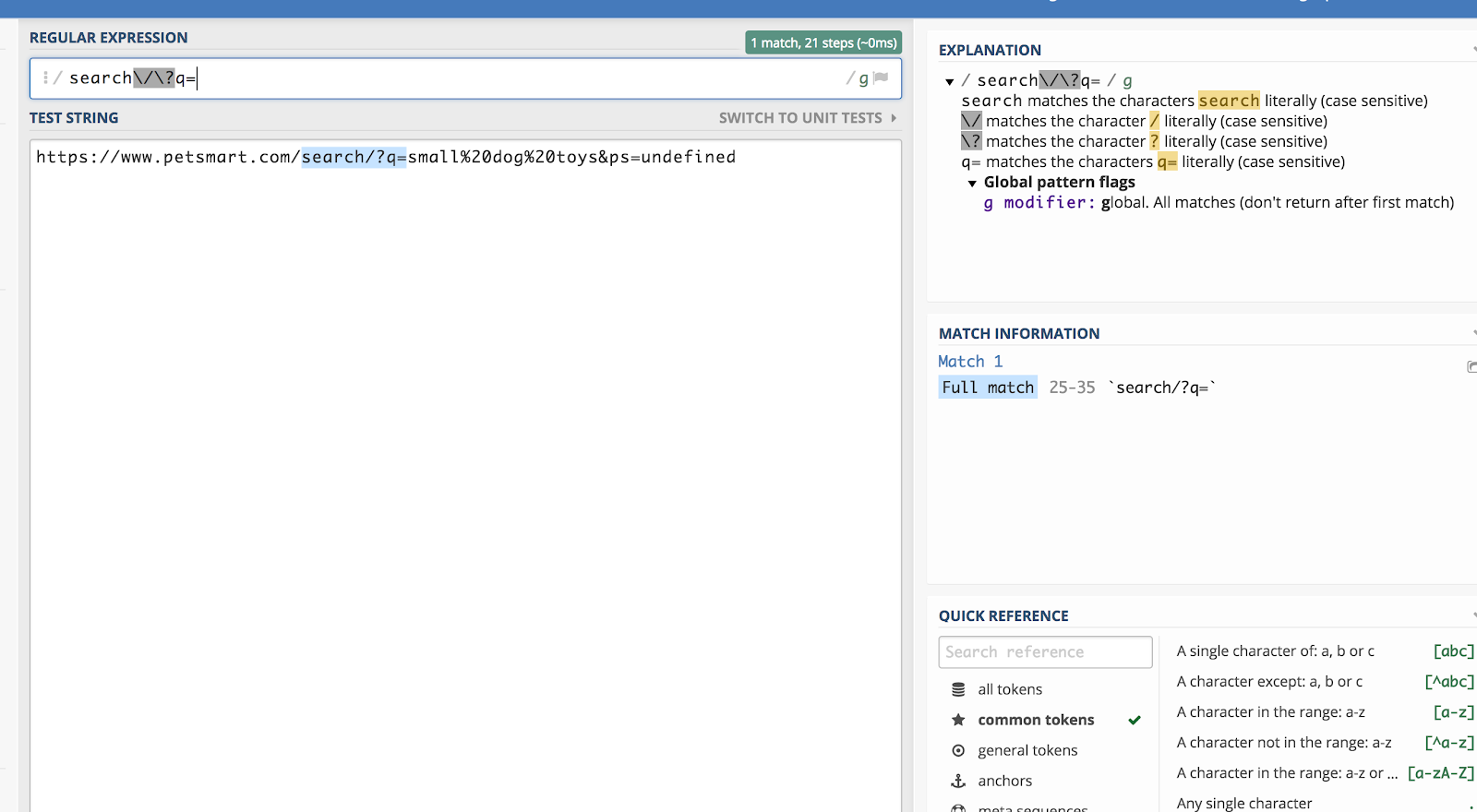
Let’s say we want to match all query strings in Google Analytics that start with /search/?q= (because that signifies a search). Then, the regular expression would be:
search\/\?q=
You can check this using a debugger like regex101.com:
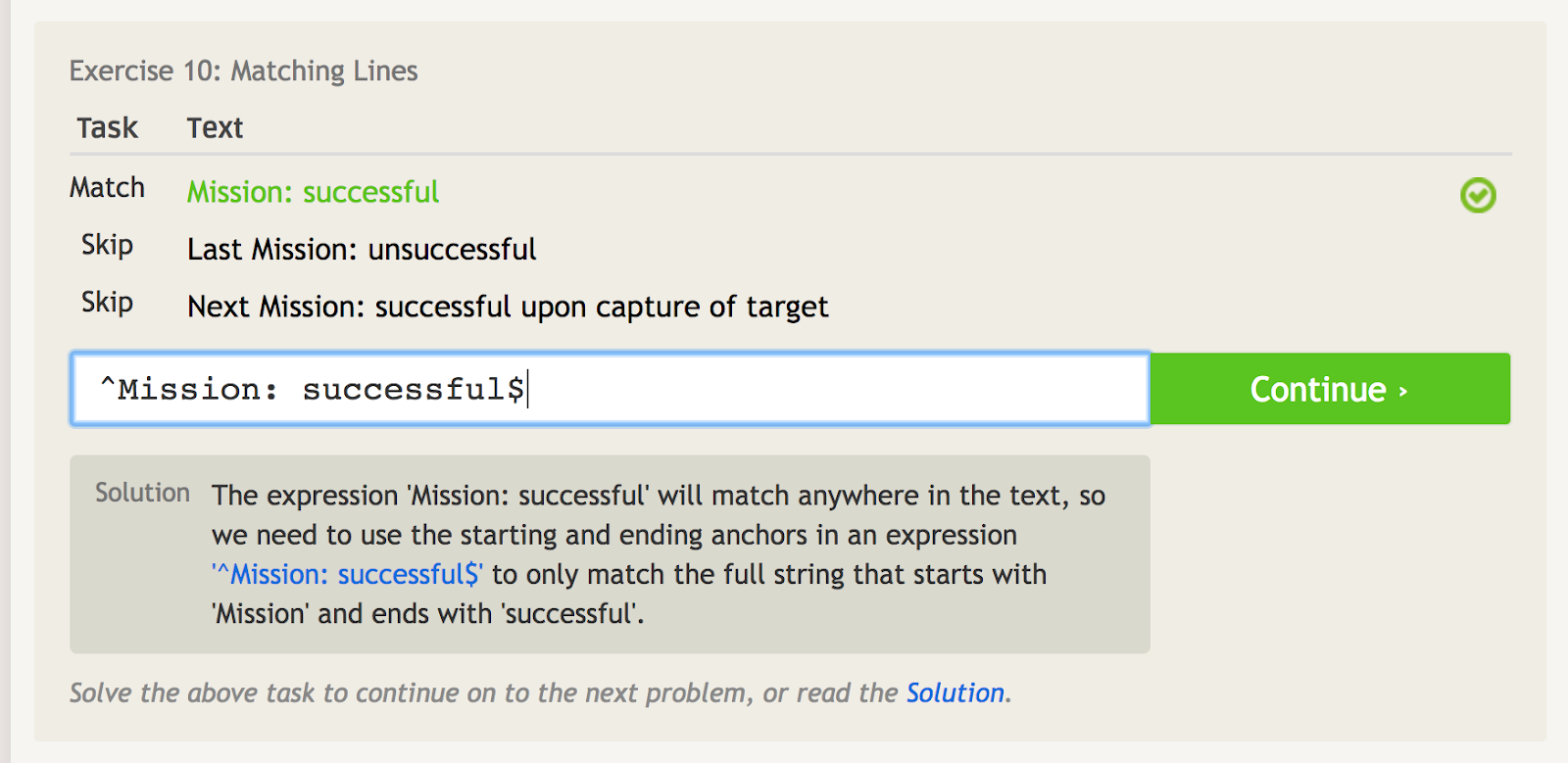
Caret (^)
Caret (^) means a phrase starts with something. This is important when you have a phrase that could appear anywhere, but you want to specifically match the phrase at the starting point. For example, take a look at this example of a few different phrases that include the words “Mission: successful.”
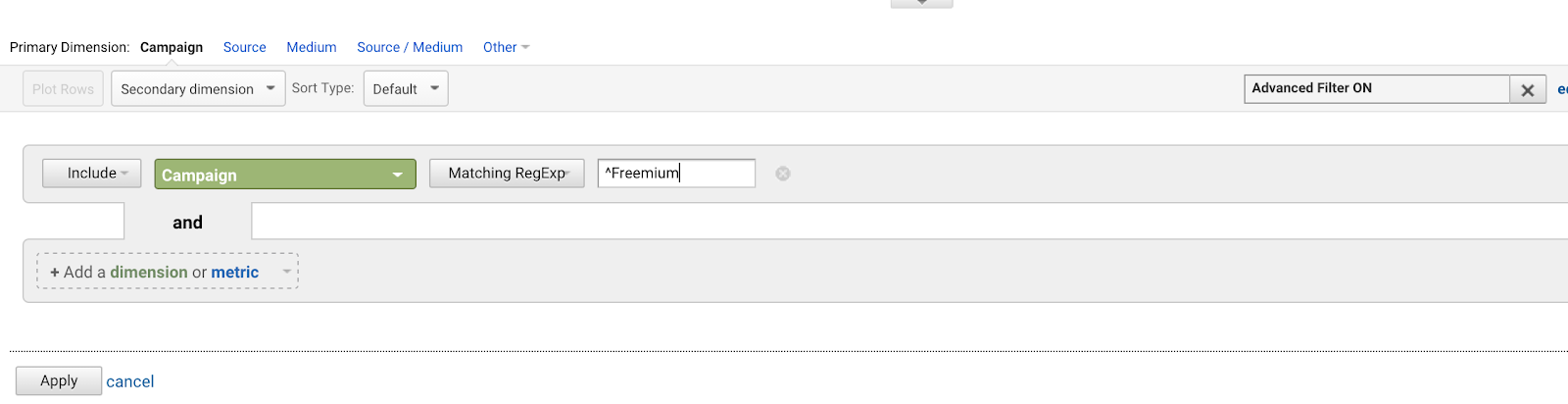
Let’s say you have a bunch of AdWords campaigns that all start with the same phrase (because you’re a bad planner for the future):
- Freemium Campaign Final
- Our first Freemium Campaign
- Creative Freemium Campaign offer
- Test Freemium Campaign
You’d want to write ^Freemium Campaign to match the first one, and none of the others.
Dollar sign ($)
Dollar sign ($) means a phrase ends with something.
When you combine the two, you can target exact match phrasing.
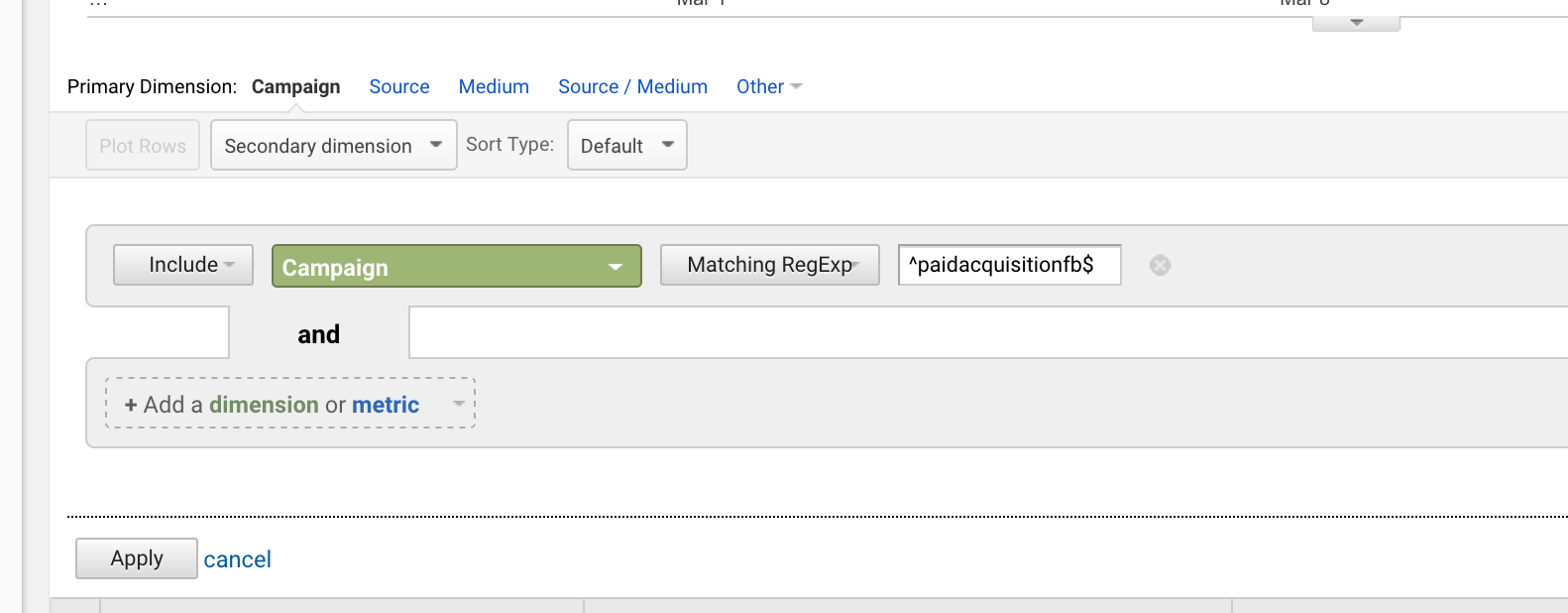
If you launched a campaign titled “paidacquisitionfb” and then later launched one called “paidacquisitionfb-2” because you didn’t plan ahead well and think you’d have other similarly titled campaigns (happens all the time), you could isolate the first by writing:
^paidacquisitionfb$
If you have tons of category pages on your blog, for instance, and they all end in a page numbers, you can write a simple piece of Google Analytics regex to view only blog category pages (^/page/[1-9]*/$). This would give you listings like:
- /page/1
- /page/2
- /page/3
...and so on.
Dot (.)
A dot (.) matches any one character, which means anything you can find on your keyboard: numbers, letters, even whitespace. It’s not super useful on its own, but it’s used all the time in conjunction with other regular expressions, especially the asterisk (coming up next).
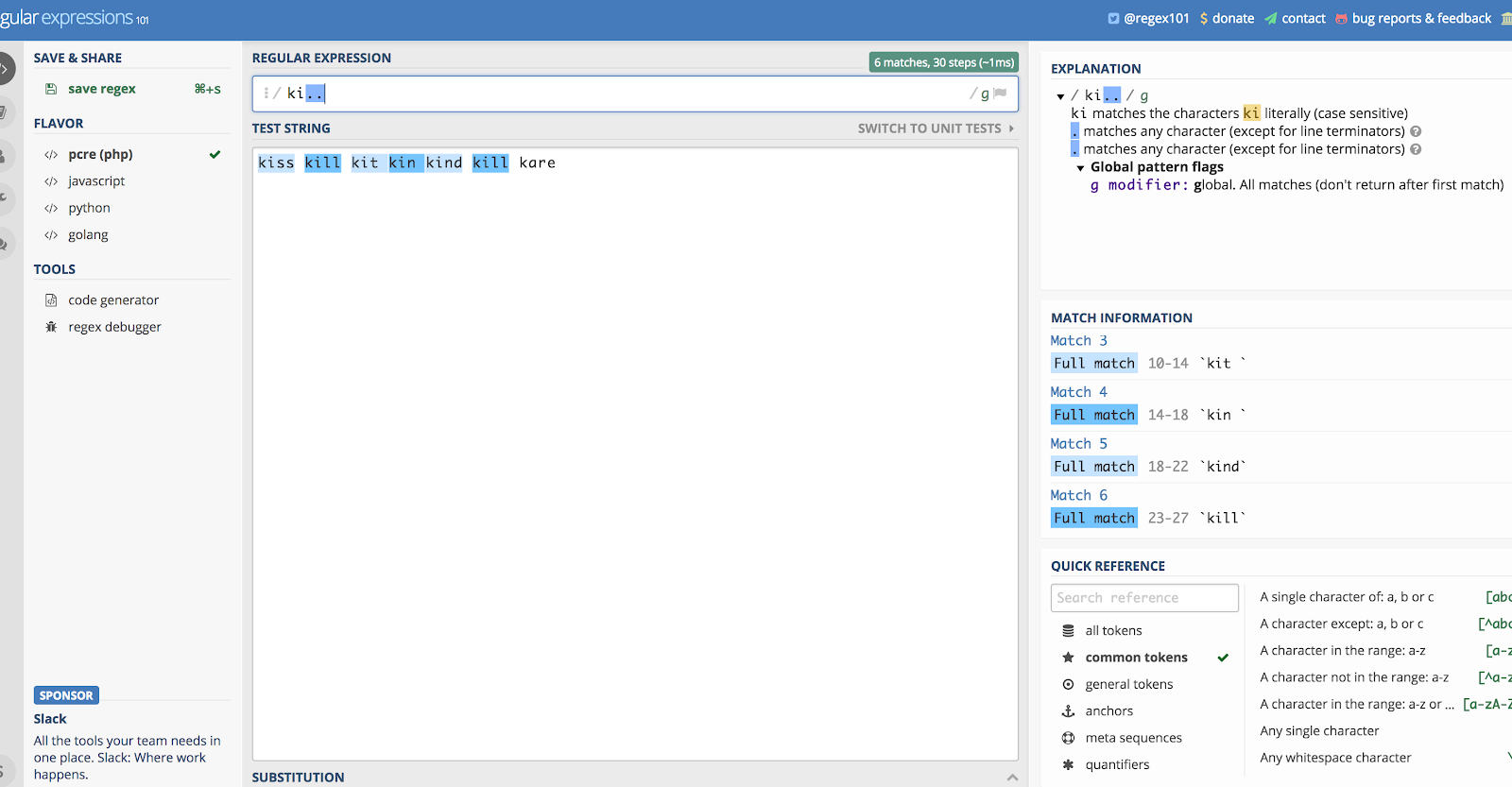
Let’s say you want to use it on its own, and let’s use the example “ki..” That would match anything that starts with the letters K and I, and then the next two characters, whatever they are.
So if you had a string that included the words kill, kind, kiss, kin, kid!, and kit, it would match all of them. Wait, what? Yes, it would match “kit” and “kin” as long as there is a space afterwards (it picks up the whitespace, too). Following that logic, it would also pick up the exclamation point in “kid!”
You can see why things get messy if you use this one alone.
Here’s an illustration of the above example using Regex101.com:
Asterisk (*)
The asterisk (*) matches zero or more of the previous items. Kind of confusing when you state it this way, so I’ll just use an example.
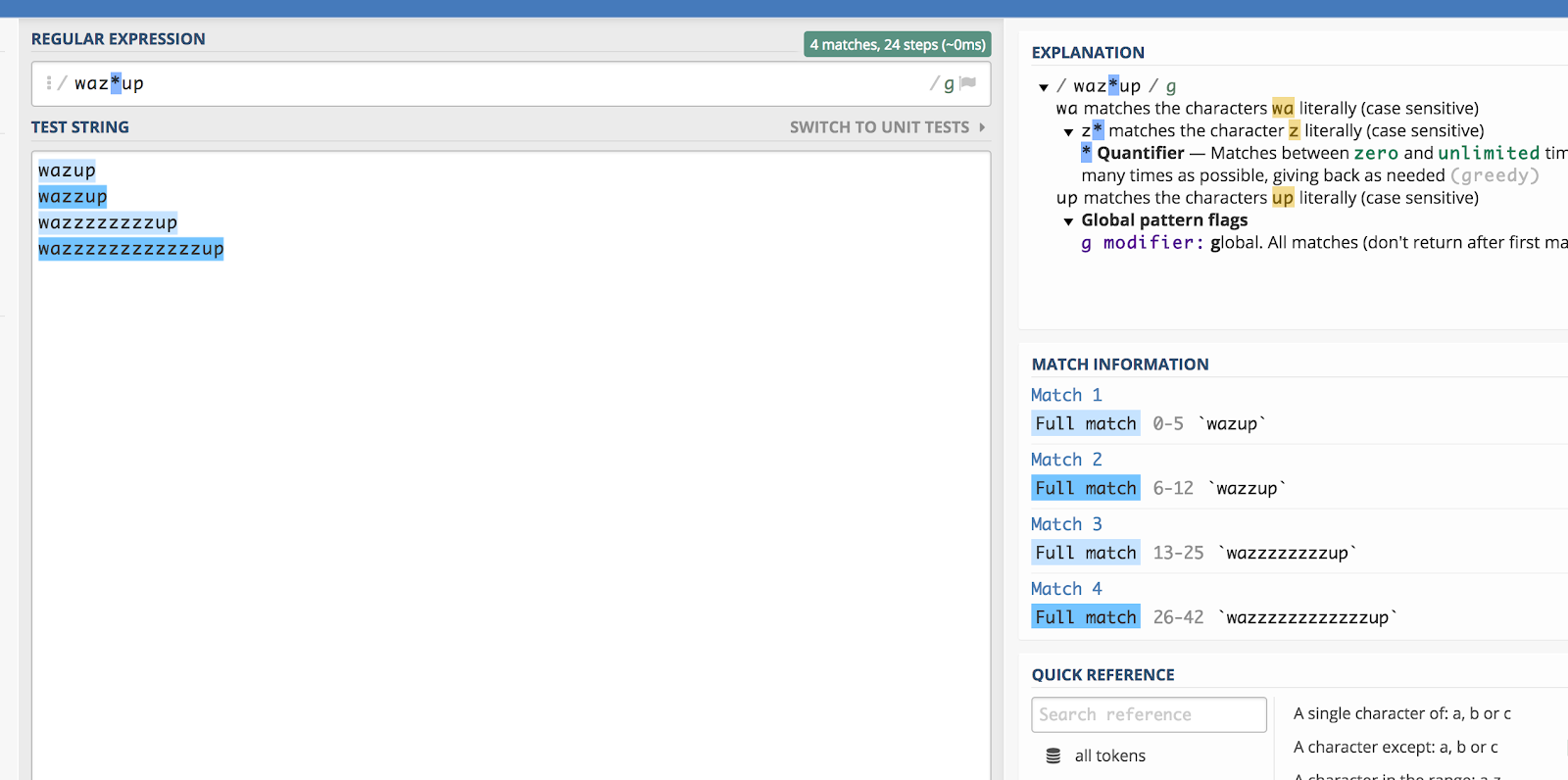
Remember that “wazzup” commercial from Budweiser a while ago? It would be pretty difficult to guess at how someone would spell that phrase if they were searching for it (say, on YouTube). But you could theoretically encapsulate all spelling variations by doing this:
waz*up
Here’s an illustration of how that works out in regex101:
If you want to get super accurate and account for upper and lower case characters, you can write something like this:
[wW][aA][zZ]*[uU][pP]
But I digress.
Where the asterisk is actually most powerful and more commonly used is with a dot or as part of other regex combinations.
Dot-Asterisk combination (.*)
The dot asterisk combo (.*) basically means anything goes. It’s very commonly used.
You’d use this combo when you want to match anything in a string. Since the dot means match whatever character, and the * means match zero or more characters before it, this combo is very powerful.
Example: you have several different types of customer accounts, but you’d like to see your data for all of them. They all have similar pages, so your pages look something like this:
/customer/pro/login/
/customer/free/login/
/customer/starter/login/
You can write the following regex to do that:
/customer/.*/login
I commonly use this Google Analytics regex expression to set up segments for users with a user ID.
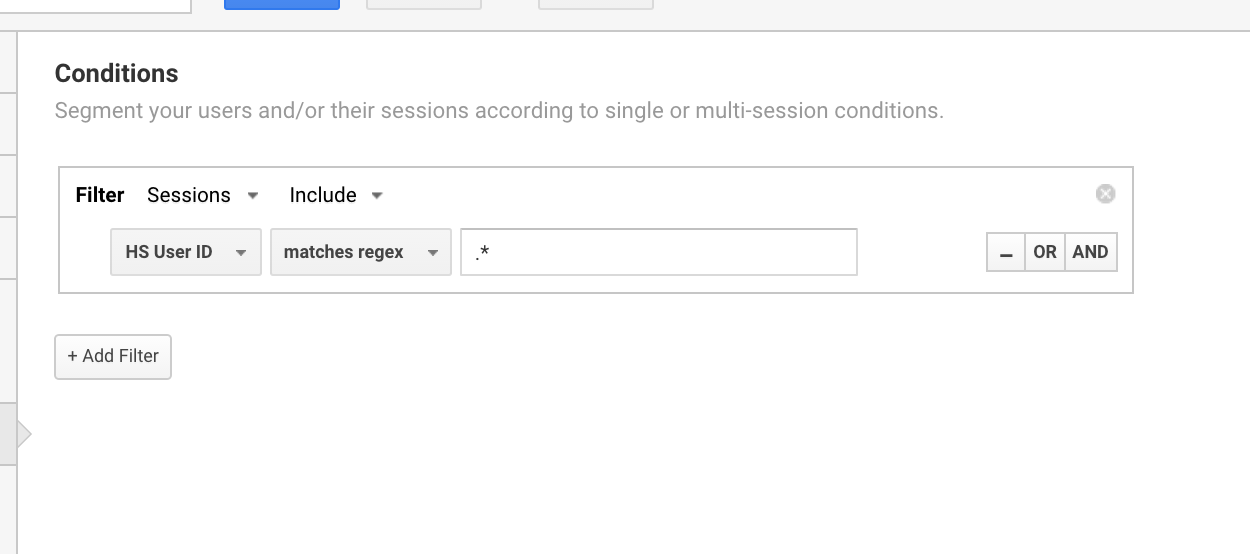
Plus sign (+)
The plus sign (+) is very similar to the *, except it matches ONE or more of the previous characters. There’s not much more than needs to be said on this one, only that it’s very slightly different than the asterisk. Here’s the difference:
Imagine you have the words: hello, hhello, and hhhello.
If you write hh+ello it will match only the second two, but if you write hh*ello, it will match all of them.
Minor distinction. In reality, I almost always use the asterisk instead of the plus sign.
Question mark (?)
The question mark (?) is an easy one. It simply means that the last character is option.
Say you don’t care much if the word is plural or not (as with shoes). It can be “shoe” or “shoes,” and you want to capture it either way. Then, you can write “shoes?”
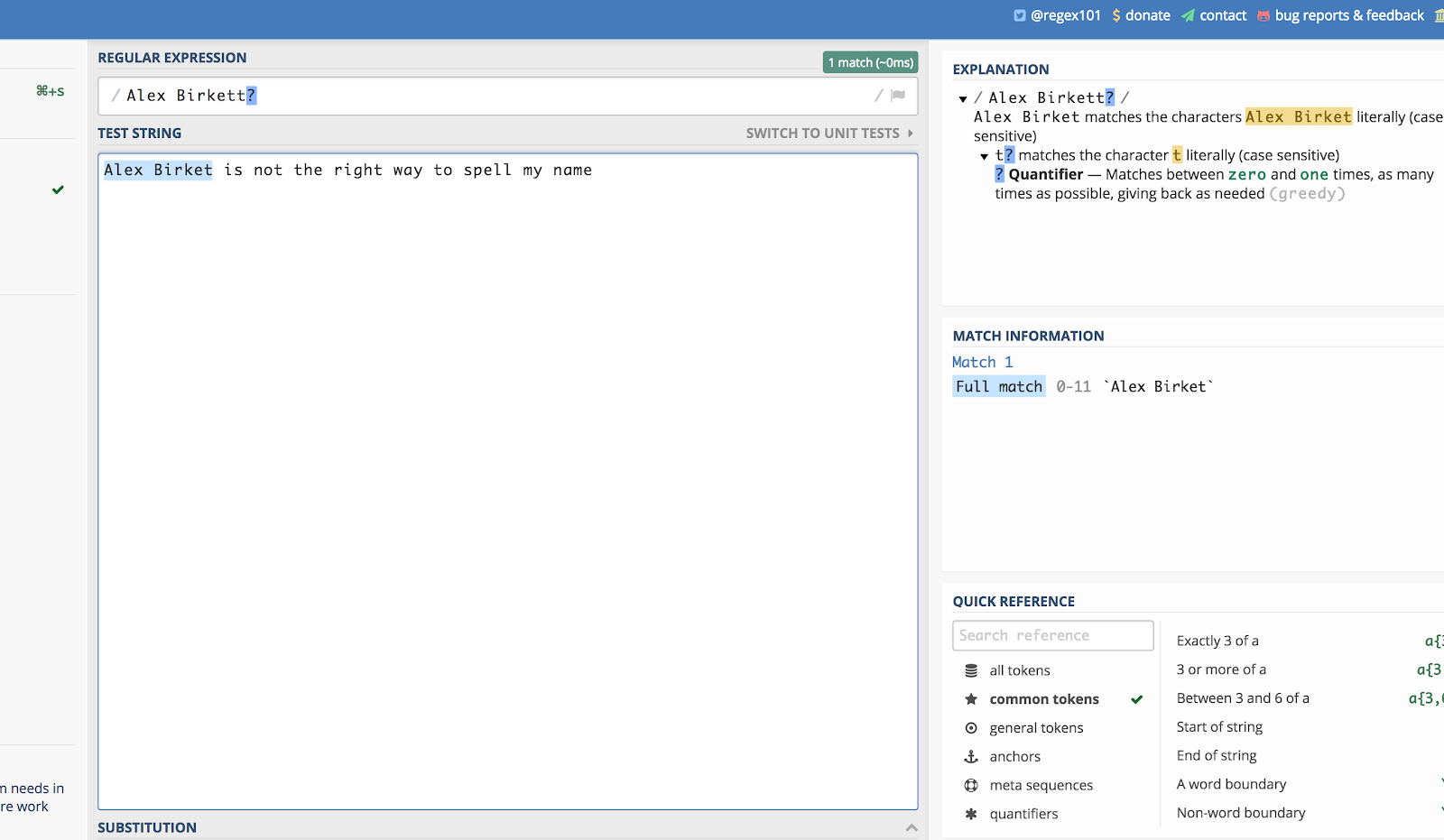
Here’s an example using my name. If someone spelled it “Alex Birket” during a site search, I’d probably still want to see that. So I can write:
Alex Birkett?
Here’s how it looks in regex101.com:
Parentheses ()
Parentheses operate the same way they do in mathematics. They tell you to prioritize and isolate the logic that it is at play inside of them.
Let’s say you have a SaaS company with three offerings and you want to match all of your pricing pages. Your URLs are as follows:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/email/pricing
To snag all three of those, you could use a regular expression like this:
^/products/(meetings|crm|email)/pricing$
Square brackets ([])
Square ([]) brackets create a list. If you have three strings, “thing1,” thing 2,” and “thing3,” you could match them all by writing “thing[123]” or “thing[1-3]” (more on dashes in a bit - they’re commonly used with square brackets.
Square brackets can be used to match several iterations of a word or string, while also excluding several other iterations. For example, if you want to match “can,” “man,” and “fan,” but not “dan,” “ran,” or “pan,” you could use the following regex to do that:
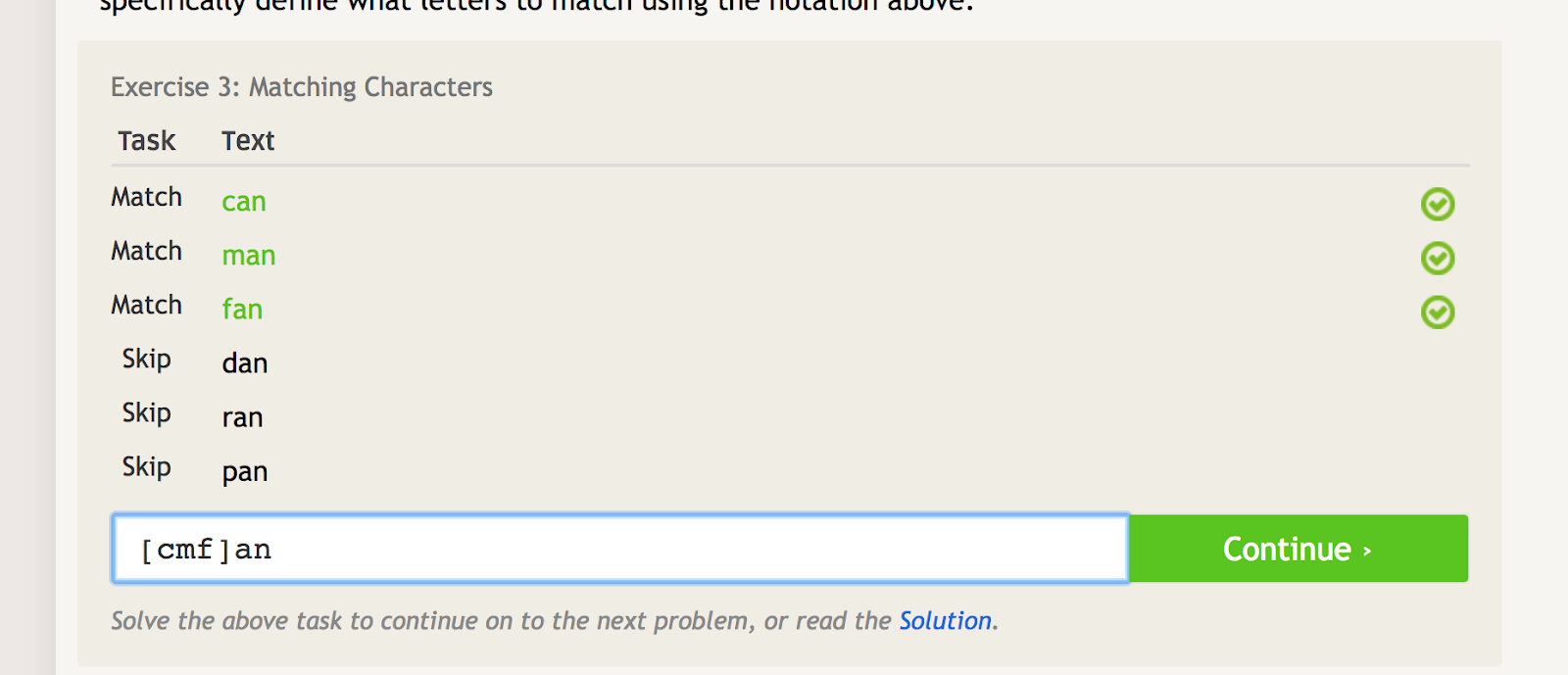
This is something you may use if you have a few different products with similar names, like “shoes1,” shoes3,” and “shoes5.” You could match those, and nothing else, using “shoes[135]”
Dashes (-)
Dashes (-) work to create linear lists of items.
As in, when you’re using square brackets, you don’t have to simply list everything out if it occurs linearly. So if you wanted to match a string of numbers where the last one could be anything from zero through nine, you could write this:
1234[0123456789]
Or, you could write the much simpler:
1234[0-9]
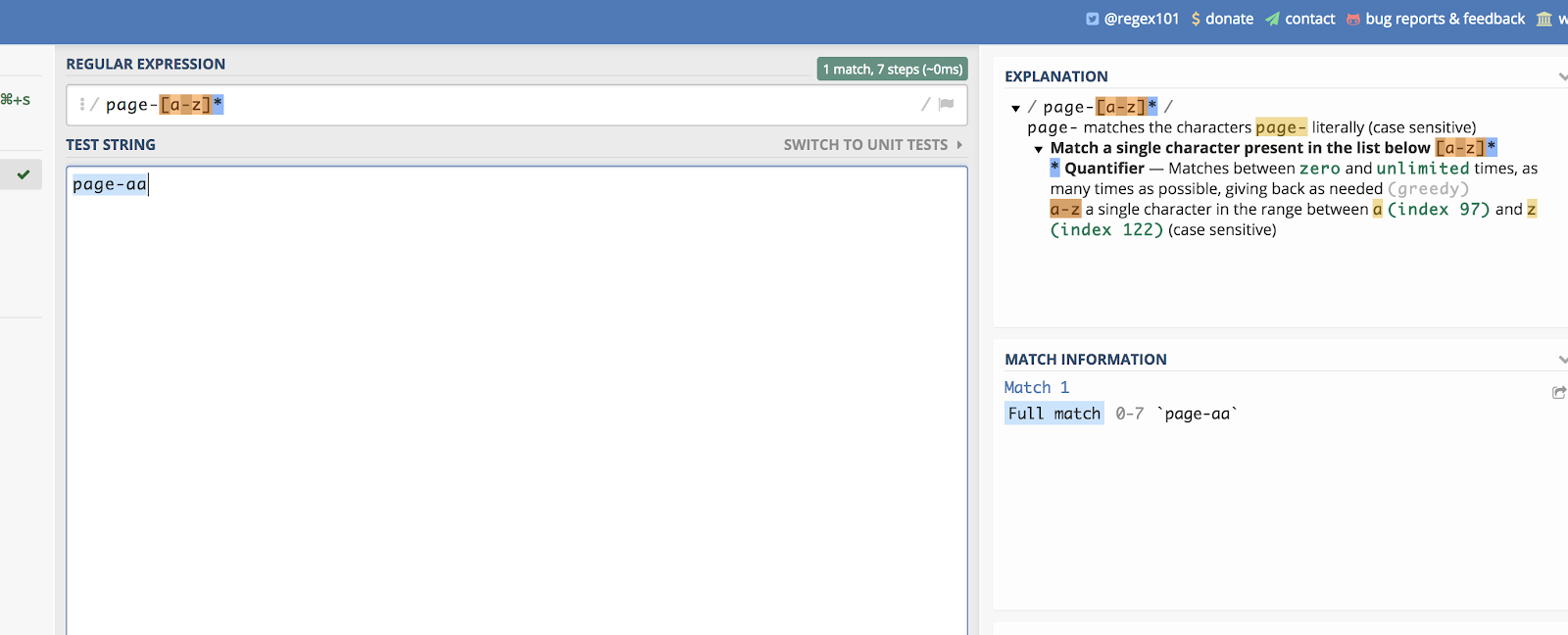
This works for letters, as well. Let’s imagine you have a page category that ends in two random letters. Something like this:
/page-aa/
You can match all of those by writing:
/page-[a-z]*/
You can see an example of that on regex101 here:
Curly brackets ({ })
Curly brackets ({}) tell you how many times to repeat the last item.
For instance, if you want to match only “wazzzzup,” you could use “waz{4}up”.
But if you wanted to match “wazzzzzup,” and “wazzzup,” but not “wazup,” you could use “waz{3,5}up”. This is basically saying to match the character “z” no less than 3 times, but no more than 5 times.
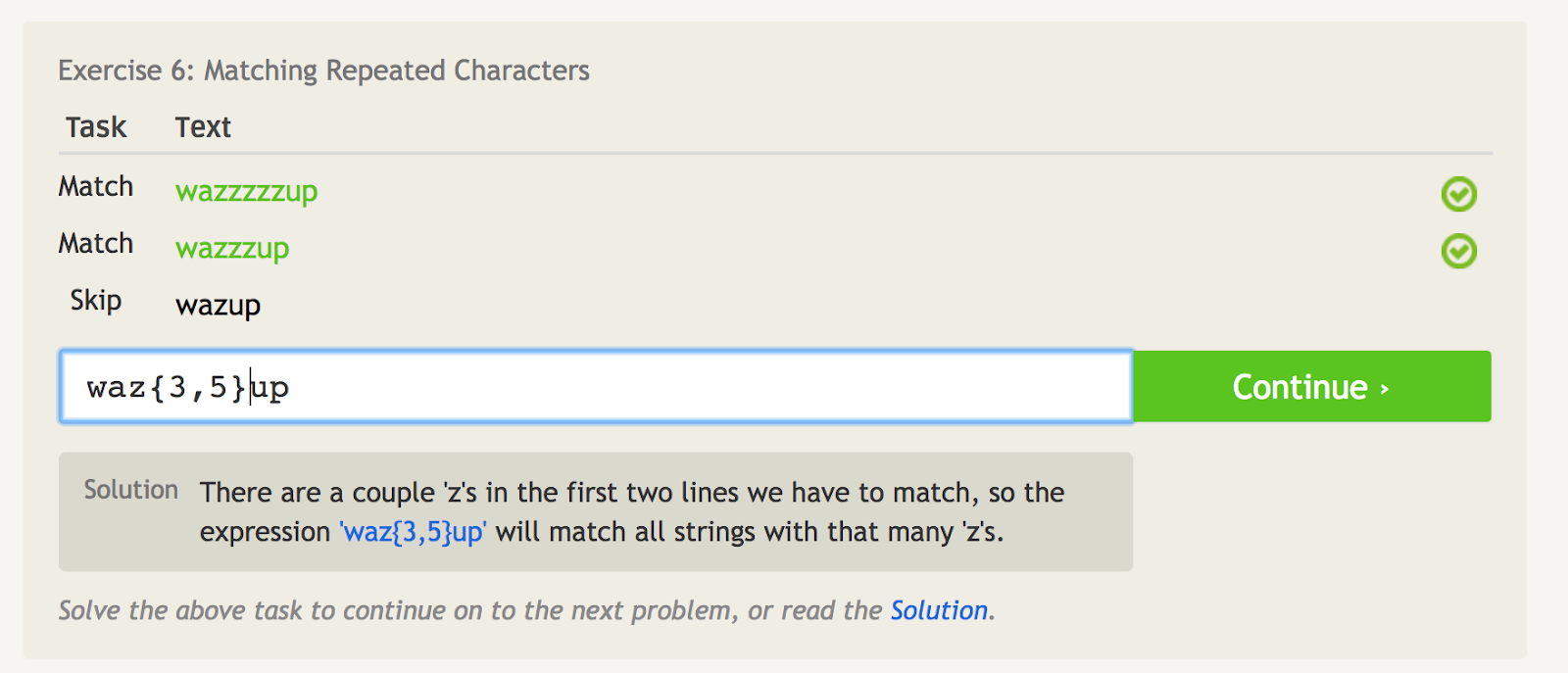
I really haven’t used this regular expression much in Google Analytics, but a common use case might be for zip codes. Usually, the first two characters are the same in a city (78--- for Austin, TX, for example). So you could match any Austin, TX zip code by writing:
78[0-9]{3}
This says the last three letters can be any random number from zero through nine.
Google Analytics RegEx: Specific Examples You Can Use
One of the most common Google Analytics regex use cases is to build out filters. Let’s walk through three examples, one simple and one a bit more complicated.
First, an example inspired by a great post on Search Engine Land by Jenny Halasz.
Let’s say you have a messed up site architecture, but you want to look at all posts with a certain subdirectory. It could be anything, say a site category or type of content. In this example, we’re looking for a category on the site for /music/, but only in the third subdirectory. In this case, you can write ^/.*/.*/music/.* and it will give you that report.

It looks confusing at a glance -- but after learning what these regular expressions mean, it’s pretty straightforward. Basically, we’re just telling GA to match landing page that starts with (^) a slash, then any characters (.*), then a slash, then any characters (.*), then a slash, and then music.
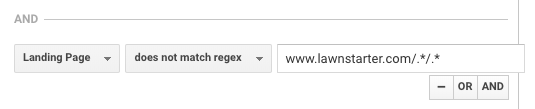
LawnStarter uses a similar tactic for reporting. Their strategy is to create city specific content in theon a subfolder of their city pages, using the following format:
https://www.lawnstarter.com/{{ transactional city page }}/{{ informational content piece }}
In order to filter out the content from conversion funnels and traffic reporting, they use the following regex, according to founder Ryan Farley.
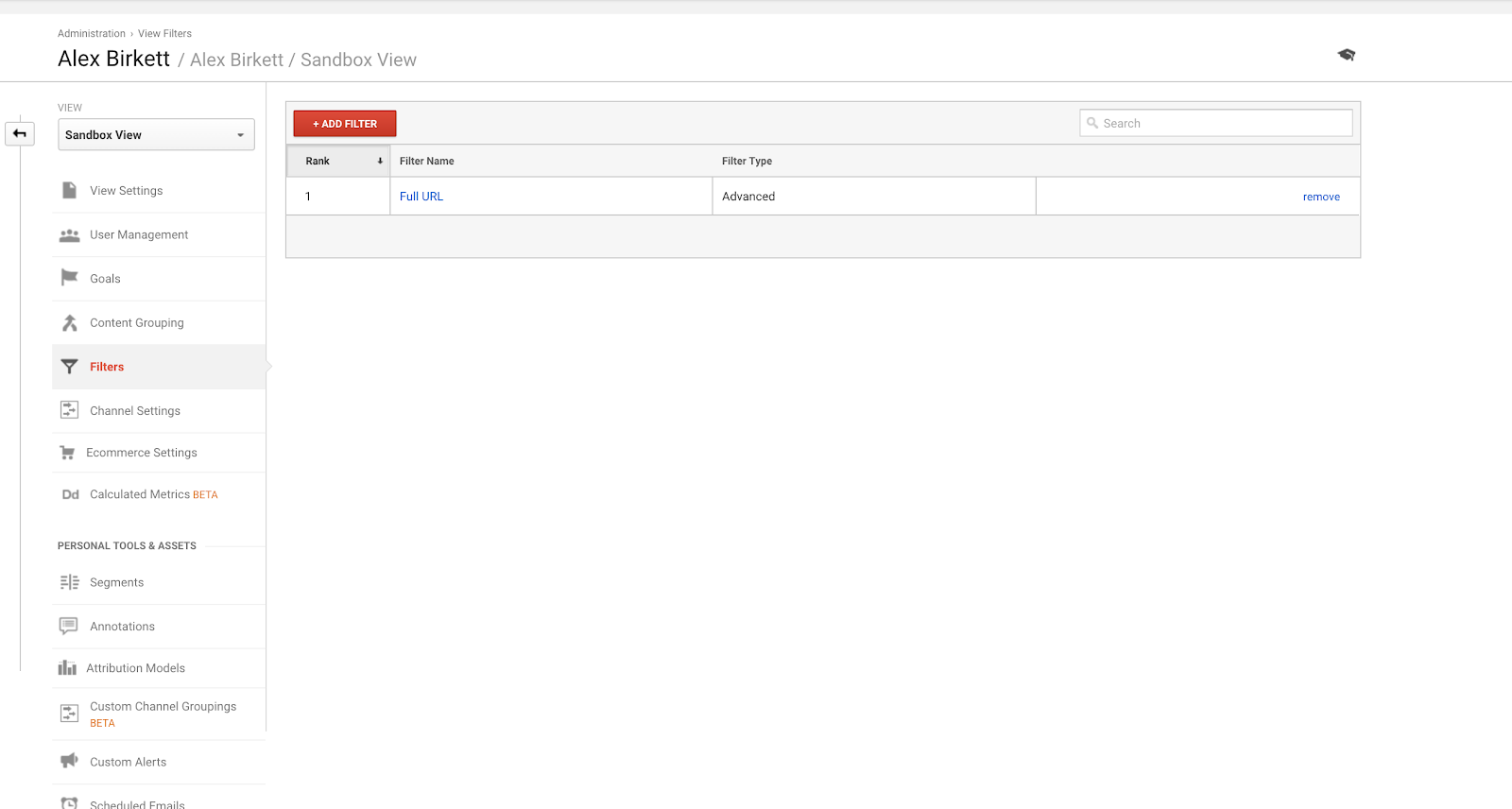
Second, let’s walk through how to set up a filter for one of your Google Analytics views. It’s likely you’ll have an implementation specialist that does this--but if not, always measure twice and cut once here. It’s easy to mess these things up (which is also why you should set up your Google Analytics account with a sandbox view to try things out first).
To set up filters, go to Admin > Filters > Add Filter.
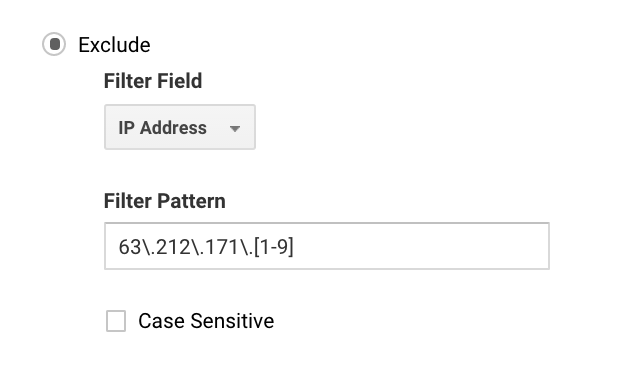
The most commonly used filter used in Google Analytics is probably to exclude traffic from your own IP address(es).
For many, you can set this up simply, because you only have one IP. For bigger companies, you may have a series of IPs, and you can set up exclusions more easily with Google Analytics regex.
For example, if you wrote 63\.212\.171\.[1-9], that would exclude all IP addresses from 63.212.171.1 to 63.212.171.9.
Another thing you can do with Google Analytics regex is set up filters to clean up query parameters.
This can be both annoying and problematic for your data analysis.
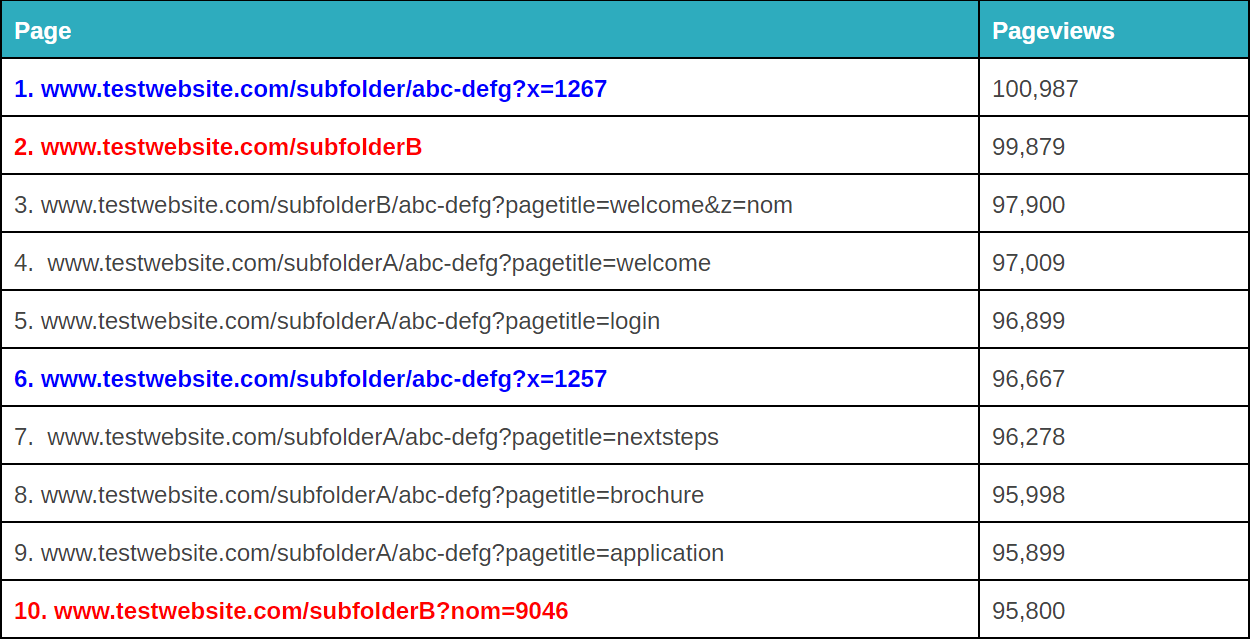
It will depend on how your specific situation is, but there are a few different ways you can use regex to clean that up (note: you can also do this in Google Tag Manager or Excel, depending on the extent of the problem. More on that here).
Finally, let’s talk about one example we can use to better organize our subdomain tracking. If you have multiple domains or subdomains, it’s possible you’ll have duplicate URLs unless you set up a filter to prepend your hostname to your request URi. In other words, you might have to URLs:
- site.com/about
- blog.site.com/about
These represent two different pages (one is a page about your company and the other is an about section for your blog). But they’d both be seen in Google Analytics as /about, unless you set up the following filter (using dot-asterisk combination Google Analytics regular expressions):
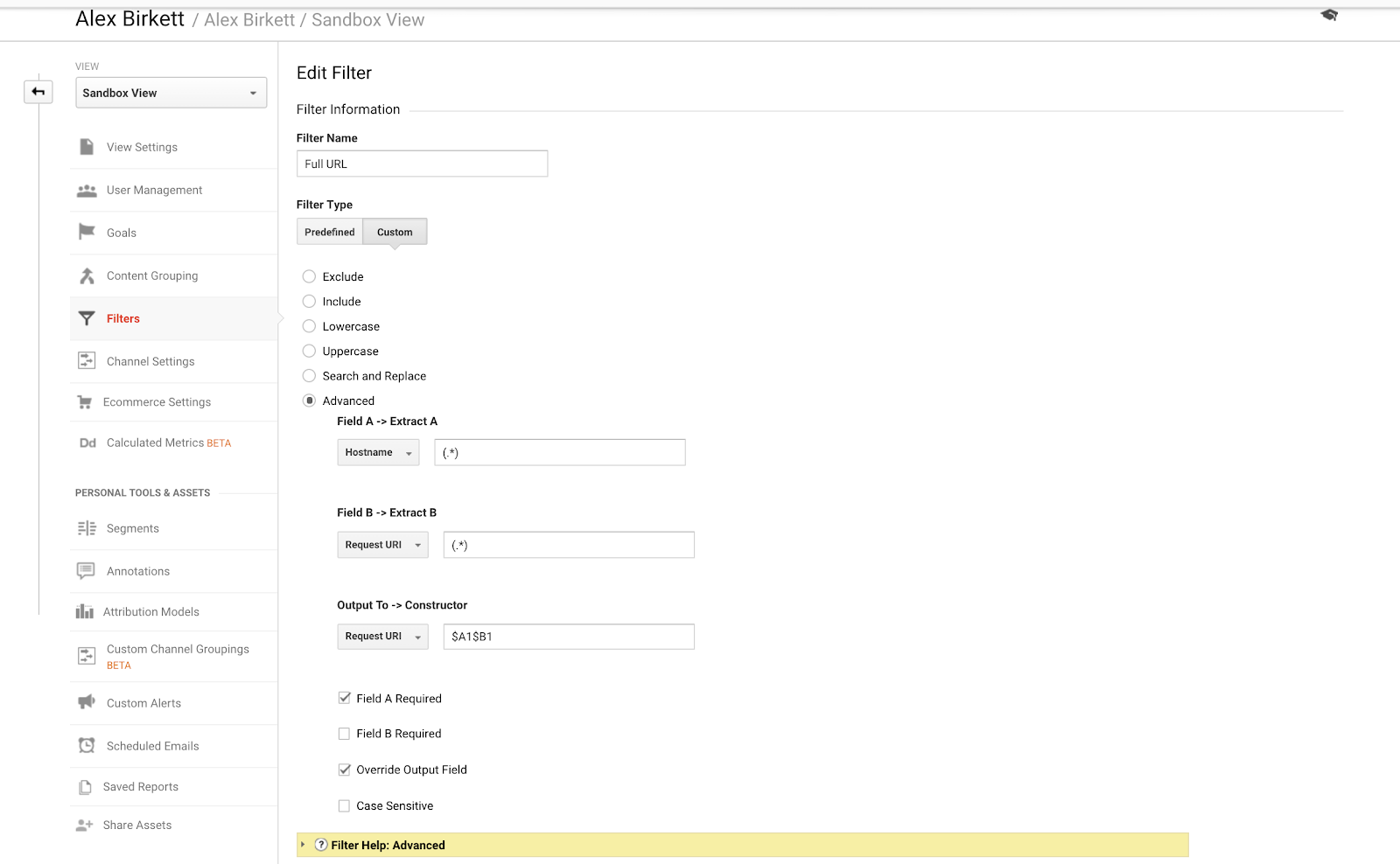
We’ve actually already covered how to set up these filters pretty in-depth in a previous KlientBoost post on cross-domain and subdomain tracking.
Google Analytics RegEx Tips & Mistakes to Avoid
Regular expressions are one of those things you just have to practice and get your hands dirty to learn. As such, you’re going to make mistakes.
That’s the most important tip, really: try things out and see if they work. I’ve listed tons of resources in this post on how to test your regex, from regex101.com to regexbuddy.com. Dip your toes in and use these resources.
However, with some foresite and heuristics, you can learn more quickly and catch more mistakes.
One thing to really learn is how to “escape” in regex (we talked about this about with the backslash). Leho Kraav, CTO at CXL Institute, puts it like this:
“I would say "learn about properly escaping things" -- it's easy to get mismatches when the characters are the same, but their meaning is different depending on whether escaped or not.”
For instance, if your query has a question mark, that’s also a regular expression so you need to make that clear with the backlash. Chris Mercer, founder of MeasurementMarketing.io, also says not learning this capability is one of the biggest mistakes he sees beginners making:
"The most common mistake we see with beginner's using regex is forgetting to "escape" regex symbols. For example, if you are looking for pages that matches regex "thankyou/?success=yes", it won't work. The "?" itself is a regex symbol, and needs to be deactivated by using the "escape character" (the " \ ". In this case "thankyou/\?success=yes" would work."
Another tip? Keep it simple. People try to complicate things (check out the most complicated regex you’ve ever seen, written by Leho, here), but regular expressions are “greedy” and will match as much as they can. Google Analytics put out a blog post of tips and explained it like this:
“If you need to write an expression to match "new visits", and the only options that you will be matching against are "new visits" and "repeat visits," just the word "new" is good enough.
They will match everything they possibly can, unless you force them not to. If your expression is "visits", it will match "new visits" and "repeat visits." After all, they both included the expression "visits." To make them less greedy, you have to make them more specific.”
So start slow, keep it simple, and don’t overwhelm yourself with complexity (the chance of error correlates with complexity in this case).
Mercer also reiterates this point, advising to take things gradually:
“When you first start out, focus on getting good... then get better. It's easy to get overwhelmed with all the different possibilities that regex offers you, but if you just start with the basics, like mastering the symbol for "or" (the " | ") you quickly get experience and begin to realize what’s possible with regex."
Final tip from me: learn to Google stuff. This is true of any programming, but especially for regular expressions. You’re going to forget things, and if you don’t write regex daily, there’s not really a point in memorizing everything. Learn to look things up and find answers to what you’re trying to do.
Outside of Google Analytics: RegEx for Other Marketing Uses
Regex is also something all SEO practitioners should look into. First, obviously, because SEO and digital analytics (e.g. Google Analytics) are inextricably intertwined. Second, because some of the same matching expressions we write to filter and match characters on our Google Analytics data can also be used in data extraction for SEO tactics.
In other words, regular expressions are important for web scraping.
In case of web scraping and SEO, you’ll usually be working through a programming language like Python, but the principles are the same.
As an example, you could scrape all bolded text on a page by using this:
<strong>([^<]+)</strong>
Or as mentioned in this SEJ article, if one were scraping ESPN for all authors, one could write this:
"columnist":"(.*?)"
For the sake of cohesiveness and sanity, I won’t dive all the way into advanced web scraping. Suffice to know regex is important in this area, too. However, if you’d like to learn more, I suggest these sources:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
Regular expressions also help you work with your SEO data, beyond simply scraping the web. For example, you can use regex to further customize how you’re using Screaming Frog.
Jenny Halasz gave a good example of using regex to clean up data in a Search Engine Land post:
“For example, let’s say you have a list of URLs and you need to break them down into just the TLD (Top Level Domain).
You can use a simple find/replace for http and www, but how do you easily knock all of the filenames off? You could remove all of them manually, but that’s a pain. Using a simple regex wildcard (/*), you can drop the slash and everything that comes after it.”
We could talk forever about regular expressions for SEO and web scraping, but I’ll just link out to some good resources in case you want to learn more (it’s a very versatile language, after all, with many use cases beyond analytics):
Conclusion
Google Analytics regex is really something every analyst should know, even if you don’t fancy yourself as technical. Beyond that, knowing some regular expressions (or at least how to search for answers and apply them to the right problems) can help marketers with various activities as well.
Just saying, it’s not a very common skill set, so you’ll probably impress some colleagues with your newfound technical marketing skills.
So I urge you, start learning, and more importantly, just start practicing using regular expressions. They’re not that scary.